
Arkadaşlar merhaba, bazen sistem mühendisleri olarak, sistemlerimiz üzerinde çalışan uygulamalar hakkında hatalar ile karşılaşırız. Ve bu hataları çözmek için analiz yapar ve aksiyon alırız. Daha sonra bu aksiyonlar sonrasında problem çözülür yada analizlerimizi daha detaylandırır ve çözüm için muhakkak sonuca ulaşmak adına destek ekibi ile kayıt açarak iletilşime geçeriz. Bugün bu yazımda ilk aşama olan ve ilk baktığımızda anlayacağımız şekilde bir analizi AI modeli yapmak üzere bir sistem kurmak istedim ve adımları aşağaıdaki şekilde paylaşıyorum. Umarım faydalı olur.
Gereksinimler,
Logları depolamak için 1 instance olacak şekilde Elasticsearch,
Elasticsearch için UI olmak üzere Kibana,
Örnek log oluşturmak için bir Python Kodu,
Localde çalışan LLM Modeli(TinyLLM),
Log analizi yapan Python Kodu,
Deneme yapmak için bir kaynağınız yok ise Google Cloud ücretsiz denemeyi kullanabilirsiniz. Burada Vm instance oluşturabilirsiniz ve üzerine k8s Cluster kurabilirisiz veya GKE üzerinde podlarınızı(Elasticsearch ve Kibana) çalıştırıp VM instance üzerinde python kodlarını koşabilirsiniz.
Aynı şekilde OCP üzerinde de bu uygulamaları çalıştırabilirsiniz.
ADIM 1:
Elastic ve Kibana uygulamalarını çalıştıralım.
vim elk.yamlapiVersion: apps/v1
kind: Deployment
metadata:
name: elasticsearch
namespace: elasticsearch
spec:
replicas: 1
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:8.11.3
ports:
- containerPort: 9200
env:
- name: discovery.type
value: single-node
- name: xpack.security.enabled
value: "false"
resources:
limits:
memory: "2Gi"
cpu: "1000m"
requests:
memory: "1Gi"
cpu: "500m"vim elk-svc.yamlapiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: elasticsearch
spec:
selector:
app: elasticsearch
ports:
- protocol: TCP
port: 9200
targetPort: 9200vim kibana.yamlapiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: elasticsearch
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana:8.11.3
ports:
- containerPort: 5601
env:
- name: ELASTICSEARCH_HOSTS
value: http://elasticsearch:9200vim kibana-svc.yamlapiVersion: v1
kind: Service
metadata:
name: kibana
namespace: elasticsearch
spec:
selector:
app: kibana
ports:
- port: 5601
targetPort: 5601
protocol: TCPkubectl apply -f elk.yaml
kubectl apply -f elk-svc.yaml
kubectl apply -f kibana.yaml
kubectl apply -f kibana-svc.yamlADIM 2:
Aşağıda bir kod örneği var, bu örnek ile kodumuzu çalıştırıp 10 saniyede bir log göndereceğiz. Elastic için localhost üzerinde kurulu clusterınız var ise orada cluster ip ve 9200 kullanabilirsiniz veya nodeport yada external ip yada ingress/route adresi ile aşağıdaki kod üzerinde ilgili alanı değiştirmemiz lazım.
python3 -m pip install --upgrade kubernetes elasticsearch python-dotenvvi send-data.pyimport time
from datetime import datetime, timezone
from elasticsearch import Elasticsearch
import random
# ELASTICSEARCH CONNECTION SETTINGS
es = Elasticsearch("http://elastic_ip_address:9200")
# SPECIFY THE NAMSPACES AND CONTAINER NAME RANDOMLY
namespaces = ["default", "kube-system", "monitoring", "apps", "logging"]
pods = [
"api-gateway", "orders-svc", "payments-svc", "frontend",
"kube-dns", "kube-proxy", "node-exporter", "prometheus",
"elasticsearch", "fluent-bit", "ingress-nginx"
]
containers = ["app", "sidecar", "proxy", "agent", "worker"]
#SOME INFO MESSAGES EXAMPLE
info_messages = [
"Pod scheduled on node",
"Pulled container image successfully",
"Container started",
"Liveness probe passed",
"Readiness probe passed",
"Service endpoints updated",
"Routine health check OK",
"Rolling update in progress",
"Metrics scraped successfully"
]
#SOME WARNING MESSAGES EXAMPLE
warn_messages = [
"High network latency detected",
"CPU usage elevated on node",
"Disk usage approaching threshold",
"Backoff restarting container",
"Pod experiencing slow start",
"API server response time elevated",
"Image pull took longer than expected"
]
#SOME ERROR MESSAGES EXAMPLE
error_messages = [
"Pod restarted due to OOM",
"Node not ready",
"Kubelet crash detected",
"CrashLoopBackOff error",
"ETCD connection lost",
"High memory usage on node",
"Service unreachable"
]
#FUNCTIONS AND DEFINE FUNCTION FOR CHOOSE MESSAGE RANDOMLY AND SEND TO THE ELASTIC
def iso_now():
return datetime.utcnow().replace(tzinfo=timezone.utc).isoformat()
def pick_level():
r = random.random()
if r < 0.7:
return "INFO", random.choice(info_messages)
elif r < 0.9:
return "WARN", random.choice(warn_messages)
else:
return "ERROR", random.choice(error_messages)
while True:
ns = random.choice(namespaces)
pod = f"{random.choice(pods)}-{random.randint(1,3)}"
ctr = random.choice(containers)
level, message = pick_level()
full_message = f"{message} | ns={ns} pod={pod} container={ctr}"
log = {
"timestamp": iso_now(),
"level": level,
"message": full_message,
"source": "k8s-logs",
"namespace": ns,
"pod": pod,
"container": ctr
}
es.index(index="logs", document=log)
print("Pushed log:", log)
time.sleep(10)python send-data.pyBelirli bir süre çalıştırdıktan sonra durdurabiliriz. Elastic üzerinde loglar gözükecektir.
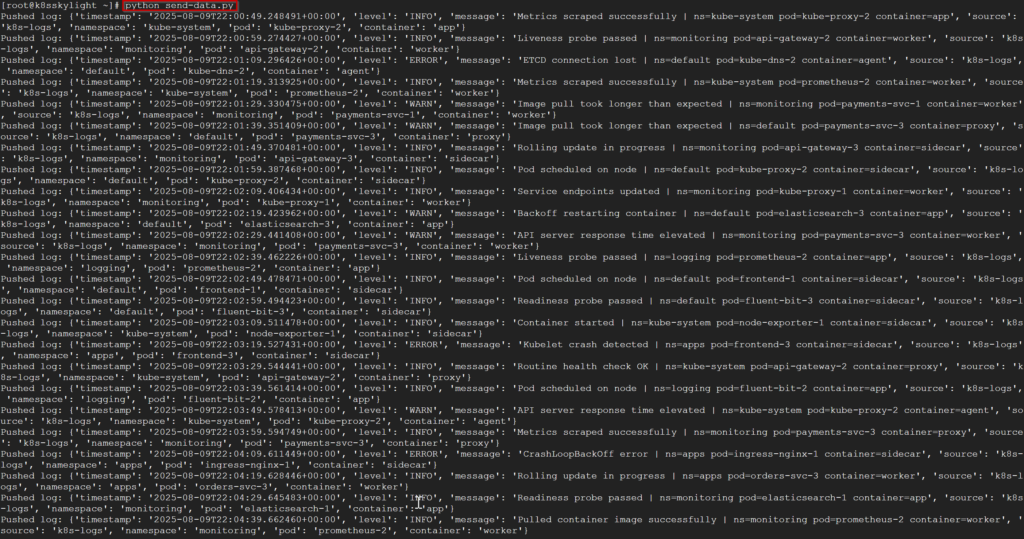
Elastic üzerinde kontrol edelim. Bu arada logs index ini visualize edecek şekilde ayarlandığını varsayıyoruz.
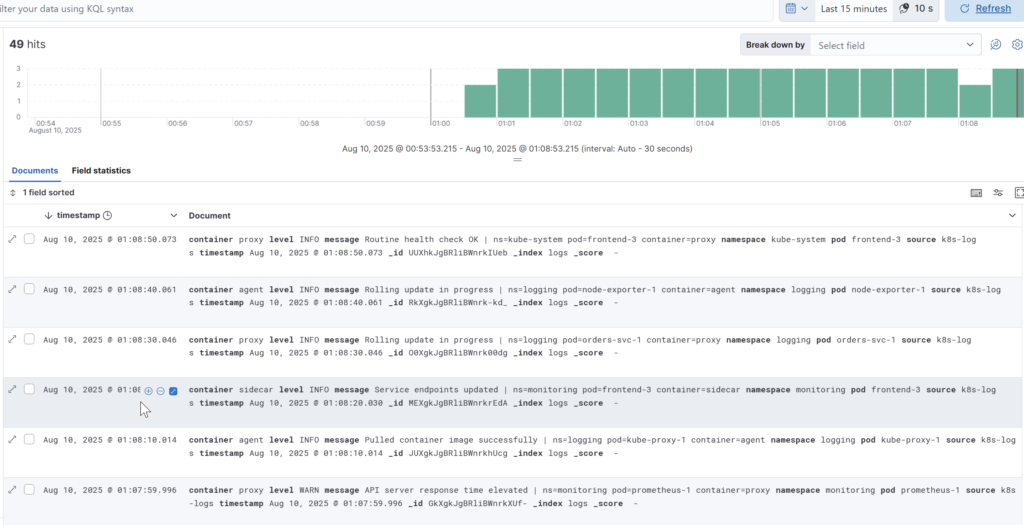
ADIM 3:
Şimdi podları loglarını analiz etmek için ollama kuracağız ve api adresi üzerinden indirdiğimiz modelin çıktısını alacağız.
curl -fsSL https://ollama.com/install.sh | sh
ollama pull tinyllama
ollama serve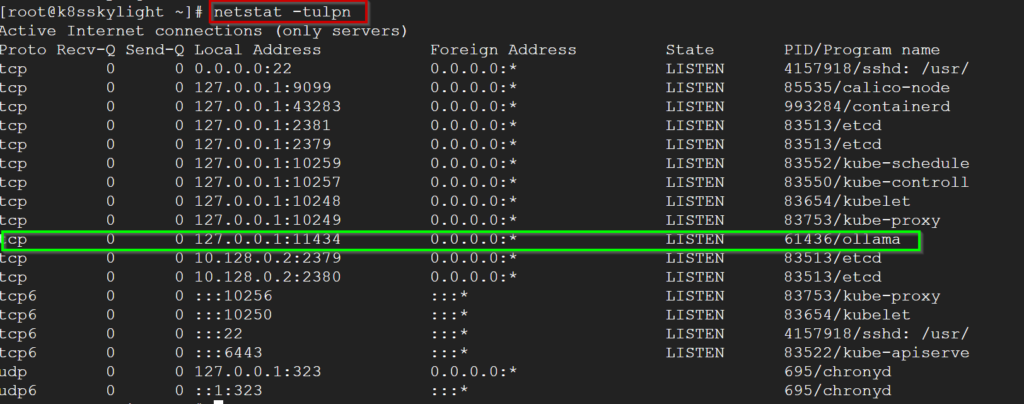
Yukarıda ollama çalışır bir şekilde ve istek alabilir durumda.
vim llm.pyimport os, json, requests, re
from elasticsearch import Elasticsearch
from dotenv import load_dotenv
from collections import OrderedDict
load_dotenv()
ES_URL = os.getenv("ES_URL", "http://10.102.163.162:9200")
ES_INDEX = os.getenv("ES_INDEX", "logs")
FETCH_N = int(os.getenv("FETCH_COUNT", "120"))
# TINY LLM MODELI kullanacağız
OLLAMA_URL = os.getenv("OLLAMA_URL", "http://127.0.0.1:11434")
LLM_MODEL = os.getenv("LLM_MODEL", "tinyllama")
es = Elasticsearch(ES_URL)
# MEsajları ayıklama ve yakalamak için
ERR_RE = re.compile(
r"(error|fail|failed|not\s*ready|crash|crashloopbackoff|oom|oomkilled|"
r"unreachable|timeout|timed\s*out|etcd|connection\s*lost|image pull back-?off|"
r"liveness probe failed|readiness probe failed|high memory usage)",
re.I
)
#Problemler içib parse etme işlemi regex ile
PROBLEM_MAP = [
(re.compile(r"not\s*ready", re.I), "NodeNotReady"),
(re.compile(r"kubelet.*crash|kubelet crash", re.I), "KubeletCrash"),
(re.compile(r"crashloopbackoff", re.I), "CrashLoopBackOff"),
(re.compile(r"\boom(killed)?|\bout of memory\b", re.I), "OOMKilled"),
(re.compile(r"high memory usage", re.I), "HighMemoryUsage"),
(re.compile(r"\betcd\b.*(lost|timeout|unreachable|fail|error)", re.I), "EtcdConnectionLost"),
(re.compile(r"service unreachable", re.I), "ServiceUnreachable"),
(re.compile(r"image pull back-?off|pull backoff", re.I), "ImagePullBackOff"),
]
CRITICAL_SET = {"KubeletCrash", "NodeNotReady", "EtcdConnectionLost", "CrashLoopBackOff"}
MEDIUM_SET = {"HighMemoryUsage", "ImagePullBackOff", "ServiceUnreachable", "OOMKilled"}
def fetch_recent_problem_lines(n=120, max_lines=20):
"""Get latest N docs, keep ONLY error-like lines, dedupe, cap to max_lines (oldest->newest)."""
body = {
"size": n,
"sort": [{"timestamp": {"order": "desc"}}],
"_source": ["timestamp","message","source"]
}
res = es.search(index=ES_INDEX, body=body)
hits = res.get("hits",{}).get("hits",[])
raw = []
for h in reversed(hits): # oldest -> newest
s = h.get("_source", {})
ts = s.get("timestamp","")
src = s.get("source","")
msg = s.get("message","") or ""
if ERR_RE.search(msg):
raw.append(f"{ts} | {src} | {msg}")
if not raw:
return []
dedup = list(OrderedDict((line, None) for line in raw).keys())
return dedup[-max_lines:]
def extract_problems(lines):
probs = set()
whole = "\n".join(lines)
for pat, name in PROBLEM_MAP:
if pat.search(whole):
probs.add(name)
return sorted(probs)
def auto_severity(problems):
if any(p in CRITICAL_SET for p in problems):
return "HIGH"
if any(p in MEDIUM_SET for p in problems):
return "MEDIUM"
return "LOW"
def make_prompt(problems, context_lines):
problems_block = ", ".join(problems) if problems else "None"
context = "\n".join(context_lines[-15:])
#Promp yazıyoruz ve modele kim olduğunu nasıl işlem yapacağınız söylüyoruz.
return (
"You are a Kubernetes SRE assistant.\n"
f"Problems: {problems_block}\n\n"
"Given the logs below, output ONLY 3-5 short, safe, actionable steps "
"to investigate/fix. Use kubectl/systemd commands. No intro, no headings, "
"no summary—just bullet lines starting with '- '.\n\n"
f"Logs (older→newer):\n{context}\n"
)
def ask_llm_chat(prompt):
payload = {
"model": LLM_MODEL,
"messages": [
{"role": "system", "content": "Return ONLY 3-5 bullet lines. No explanations, no headings."},
{"role": "user", "content": prompt}
],
"keep_alive": "10m",
"stream": False, # <— single JSON response
"options": {
"temperature": 0.1,
"num_ctx": 512,
"num_predict": 128,
"top_k": 20
}
}
r = requests.post(f"{OLLAMA_URL}/api/chat", json=payload, timeout=(10, 600))
r.raise_for_status()
data = r.json()
return (data.get("message", {}) or {}).get("content", "") or ""
def extract_bullets(text, want_min=3, want_max=5):
lines = [ln.strip() for ln in text.splitlines()]
bullets = [ln for ln in lines if ln.startswith("- ") or ln.startswith("• ") or ln.startswith("* ")]
if not bullets and text:
parts = [p.strip().rstrip(".") for p in re.split(r"\.\s+", text) if p.strip()]
bullets = [f"- {p}" for p in parts[:want_max]]
if len(bullets) > want_max:
bullets = bullets[:want_max]
return bullets
if __name__ == "__main__":
problem_lines = fetch_recent_problem_lines(FETCH_N, max_lines=20)
print("\n=== Detected Problem Logs (used in prompt) ===")
if not problem_lines:
print("(none found)")
raise SystemExit(0)
for l in problem_lines:
print(l)
problems = extract_problems(problem_lines)
severity = auto_severity(problems)
prompt = make_prompt(problems, problem_lines)
raw = ask_llm_chat(prompt)
bullets = extract_bullets(raw)
print("\n=== Problems ===")
print(", ".join(problems) if problems else "(none)")
print("\n=== Severity (auto) ===")
print(severity)
print("\n=== Advice (TinyLlama) ===")
if bullets:
for b in bullets:
print(b)
else:
print("(no advice generated)")Çıktımız aşağıdaki şekilde,
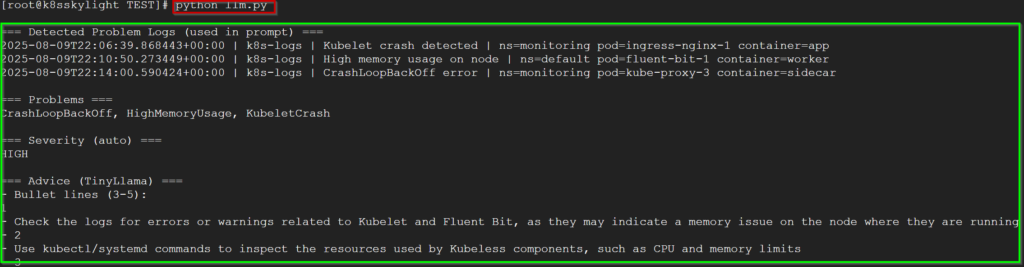
Teşekkürler.
No responses yet